)

In this blog post, I will show you how to maintain and reuse complex SQL in a Ruby on Rails application. In case you are not sure if going beyond Active Record is worth it, please read part 1.
Ruby on Rails is a fantastic framework, but there are no extra built-in features for medium-to-heavy database usage as stated in Rails Guides:
The Active Record way claims that intelligence belongs in your models, not in the database. As such, features such as triggers or constraints, which push some of that intelligence back into the database, are not heavily used.
There is a good reason for that: there is no simple way of managing and documenting database beyond the basics (by which I mean all of the things that are supported by standard Rails migrations). If I added a bunch of stored procedures and triggers in a project I currently work on, I bet the first person that noticed any of that (besides the PR reviewer maybe) would be the one debugging the code and going bonkers not being able to find any reasonable explanation of what is happening.
Get rid of schema.rb
The file called schema.rb keeps information about your… well, schema. It is a list of all database tables and indexes in the form of Rails migrations code. As this is not SQL, it can only express features supported by migrations; this is just a subset of SQL capabilities.
Unlike schema.rb, the structure.sql file in a Rails project is generated using a command from the native database engine. This means that it will have all of the schema information (like stored procedures, triggers, materialised views, etc.). It may not matter in a production environment, but you will quickly find out that something is wrong when you run your tests; Rails uses the file with schema to prepare the database.
# config/application.rb
config.active_record.schema_format = :sql
Now you can write your first migration. I won’t be using examples from my previous blog post SQL on Rails part 1: Why because the code samples are long, but all of the techniques are applicable. There are numerous ways to migrate an SQL database, but I will write about two that I think are the most convenient and the most interesting. I will also link to a few others.
Option 1: Rails migrations
Rails migrations system doesn’t support advanced PostgreSQL features. There is a simple way of executing any SQL code though. It is possible using the execute method, which will run any SQL code passed as a string. An example of such a migration file would look like this:
class CreateFooFunction < ActiveRecord::Migration[5.1]
def up
execute <<~SQL
CREATE OR REPLACE FUNCTION foo()
RETURNS text AS $$
BEGIN
RETURN 'foo';
END;
$$ LANGUAGE plpgsql;
SQL
end
def down
execute "DROP FUNCTION foo()"
end
end
This will result in the following lines being added to the structure.sql file:
--
-- Name: foo(); Type: FUNCTION; Schema: public; Owner: -
--
CREATE OR REPLACE FUNCTION foo() RETURNS text
LANGUAGE plpgsql
AS $$
BEGIN
RETURN 'foo';
END;
$$;
Whereas with the schema.rb file nothing new would show up:
ActiveRecord::Schema.define(version: 20171022164839) do
# These are extensions that must be enabled to support this database
enable_extension "plpgsql"
end
While it works, it is not that pleasant to use. It may be not very visible in this simple example, but with apps growing it gets hard to maintain. Let’s say you need to change the foo() stored procedure code to return foobar text. It is only one line of the code, but the only way to make it happen is to create another migration file with a whole stored procedure.
The distinct disadvantage is that you have to create the migration in the first place; it is only one line of code to change. The less apparent disadvantage is the ambiguity: every change creates another copy of the procedure code. The changes are also harder to track (there’s no readable diff).
While you mostly use features supported by Rails migrations and only throw in something occasionally, it might be just fine. But if you feel limited by Rails, there are other ways.
Option 2: Sqitch
With all of their ease of use, it is hard to say that Rails migrations are universal. There is a standalone migrations tool though, called Sqitch. It is based on a Git-like commands system, and it solves a few issues with the Rails migrations system.
I don’t want to turn this post into a Sqitch tutorial, especially that there is an excellent step by step tutorial for PostgreSQL on the Sqitch website. I will briefly show how to handle an example with a foo() stored procedure to show some of the advantages of Sqitch.
Skipping all of the configuration, Sqitch uses syntax similar to Git. To add a function foo() from the example above, first you would create a migration:
sqitch add adds-foo-stored-procedure -n 'Adds foo() stored procedure.'
Created deploy/adds-foo-stored-procedure.sql
Created revert/adds-foo-stored-procedure.sql
Created verify/adds-foo-stored-procedure.sql
Added "adds-foo-stored-procedure" to sqitch.plan
The migration needs to be written in deploy/adds-foo-stored-procedure.sql:
-- Deploy sqitch-test:adds-foo-stored-procedure to pg
BEGIN;
CREATE OR REPLACE FUNCTION foo() RETURNS text
LANGUAGE plpgsql
AS $$
BEGIN
RETURN 'foo';
END;
$$;
COMMIT;
The code that will revert the change sits in revert/adds-foo-stored-procedure.sql:
-- Revert sqitch-test:adds-foo-stored-procedure from pg
BEGIN;
DROP FUNCTION foo();
COMMIT;
Now, assuming that your database name is sqitch_test, you can run all the pending migrations with:
> sqitch deploy db:pg:sqitch_test
Deploying changes to db:pg:sqitch_test
+ adds-foo-stored-procedure .. ok
There is an interesting concept of verification files, which you can use to verify whether the changes were successfully applied. The verification code needs to raise an exception when the change is not applied. It goes to verify/adds-foo-stored-procedure.sql and in case of the foo() stored procedure can be as simple as:
-- Verify sqitch-test:adds-foo-stored-procedure on pg
BEGIN;
SELECT foo();
ROLLBACK;
Sqitch approach is different from Rails migrations, but there are also some similarities: instead of one file with up/down methods you have two files, one for adding and one for reverting the changes. The trace of the change is added to a sqitch.plan file:
adds-foo-stored-procedure 2017-10-29T10:52:13Z Luke Sqitch test <luke@sqitch> # Adds foo() stored procedure.
What is very interesting about Sqitch is that (similarly to Git) it uses tags to handle versions. Let’s say that the only change in the current release is the foo() stored procedure. You can add the appropriate tag to mark the release:
> sqitch tag v1.0.0 -n 'Tag v1.0.0'
Tagged "adds-foo-stored-procedure" with @v1.0.0 in sqitch.plan
In case you want to change something, it is much better just to revert the change and redeploy. This is of course not an option if the change is already in production. In this case, you can use the sqitch rework command. The rework command will only work if the change you want to make is already tagged.
> sqitch rework adds-foo-stored-procedure -n "foo() procedure should return foobar text"
Added "adds-foo-stored-procedure [[email protected]]" to sqitch.plan.
Modify these files as appropriate:
* deploy/adds-foo-stored-procedure.sql
* revert/adds-foo-stored-procedure.sql
* verify/adds-foo-stored-procedure.sql
As the message states, you can now change any of the files to alter the migration. What is essential is that you can use the rework command only if the change is idempotent, so it can be executed more than once without raising any exceptions. In our case, CREATE OR REPLACE is used so that the SQL doesn’t break when the function already exists. The interesting thing that happened is that Sqitch changed the revert script to go back to the foo() stored procedure from the v1.0.0 tag and added three files:
deploy/[email protected]
revert/[email protected]
verify/[email protected]
Thanks to those changes Sqitch will know how the foo() function looked like at version 1.0.0. Now the only change you have to make is one line:
CREATE OR REPLACE FUNCTION foo() RETURNS text
LANGUAGE plpgsql
AS $$
BEGIN
- RETURN 'foo';
+ RETURN 'foobar';
END;
$$;
After running sqitch deploy db:pg:sqitch_test Sqitch will make the change and the SELECT foo(); query will return the foobar text. Few files were changed in the process, but you had to change only one line to make a one-word change and the diff is clear; it feels better and simpler than the counterpart Rails migrations. What is very interesting is that you can easily go back to the previous version of the migration by running:
> sqitch revert --to @v1.0.0 db:pg:sqitch_test
Revert changes to adds-foo-stored-procedure @v1.0.0 from db:pg:sqitch_test? [Yes] y
- adds-foo-stored-procedure .. ok
Now running SELECT foo(); returns the foo text again.
Sqitch gives you much more flexibility and control compared to Rails migrations. It is also aware of version control, and it allows you to use all of the SQL features efficiently. The downside is the added complexity and learning curve. Rails migrations are very simple, and every Rails developer knows how to use them. I wouldn’t say Sqitch is hard, but I wouldn’t say it is as simple as Rails migrations either. It shines especially in environments where:
- there is more than one application using the database;
- there are teams not using Ruby on Rails as the primary technology;
- features not supported by Rails migrations are often used.
As I skipped configuration steps and some of the features, you may want to go to the Sqitch website or the Sqitch PostgreSQL tutorial to find out more.
Other options
As a Rails developer, I don’t think that it is necessary to use anything other than Rails migrations or Sqitch. If for some reason you don’t like either of them, there are other tools listed on the PostgreSQL wiki. There is also an interesting talk about managing your database without migrations by using diffs, called Your database migrations are bad and you should feel bad; its title is not very optimistic, but it is worth watching.
Documentation and tools
Documentation is not always the high point of Rails projects, especially if they are considered start-ups; documentation of the database schema is even rarer. When advanced SQL features are heavily used in your project, you want to make sure that that the developer team is aware of that. The best way to achieve that is to expose database documentation as much as you can.
SchemaSpy
The first tool I would recommend is SchemaSpy – it is documentation tool that generates a nice looking dashboard for your database schema. Go straight to the demo to see how it looks in action.
Such documentation will make it easier to know the details of the database schema easily, especially for developers joining the project. SchemaSpy is a great tool, but it doesn’t have support for stored procedures and triggers (it does display views though). What I recommend is to use COMMENT ON in PostgreSQL to overcome those limitations; SchemaSpy supports Markdown syntax so that you could write the following code:
COMMENT ON COLUMN articles.upvotes_count IS 'Column is updated by a **trigger** on the **votes** table.';
COMMENT ON COLUMN articles.downvotes_count IS 'Column is updated by a **trigger** on the **votes** table.';
COMMENT ON TABLE votes IS '
#### General description:
This table represents upvotes and downvotes for records in `articles` table. When `up` flag is `true` record represents upvote and downvote otherwise.
#### Triggers list:
* update_article_votes_count after insert, delete -> update_article_votes_count_trigger';
This will result in following SchemaSpy output:
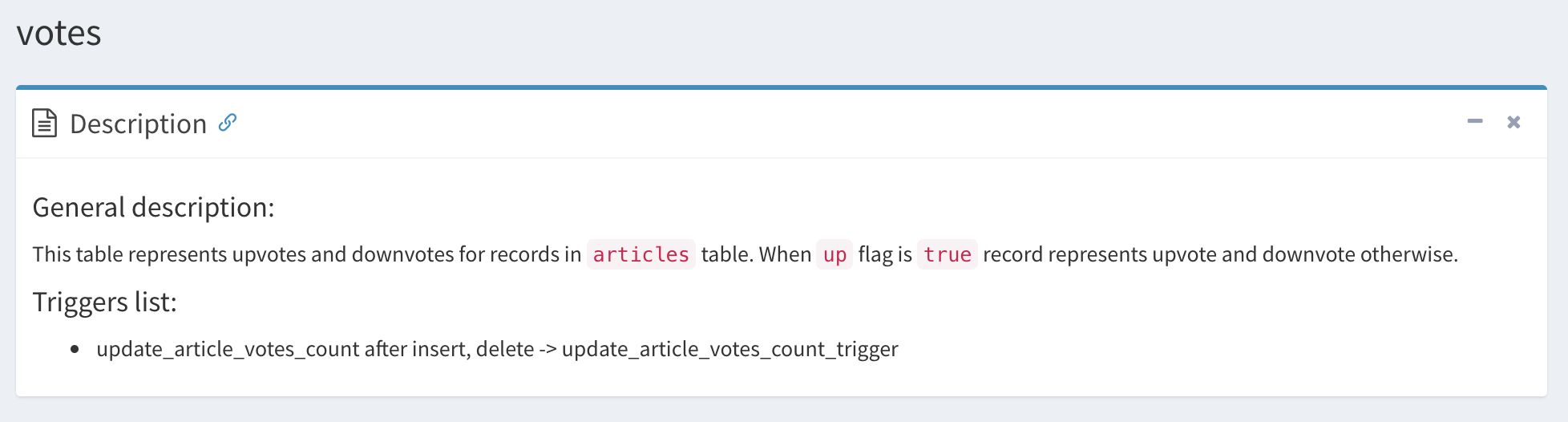
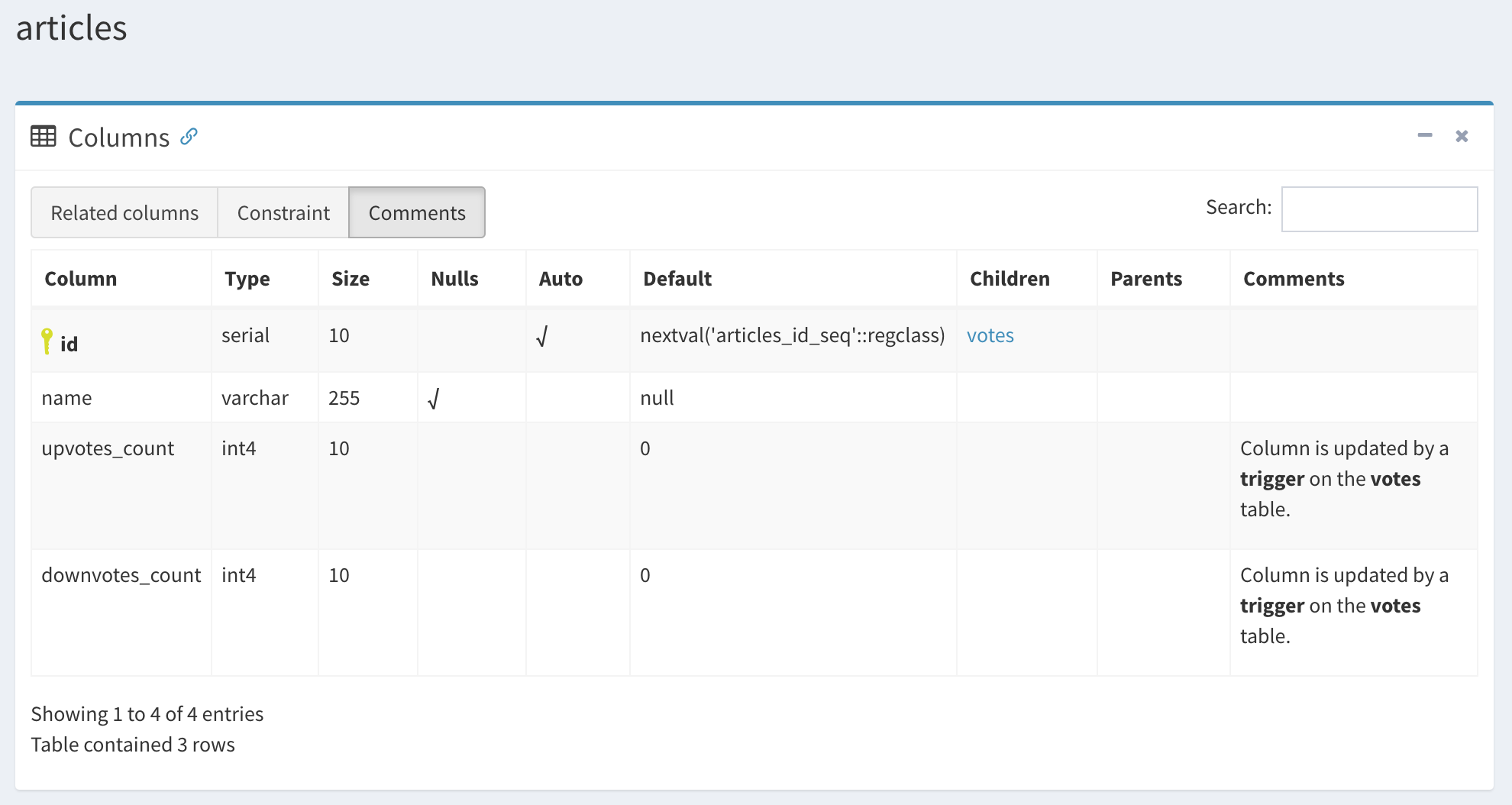
As you can see, SchemaSpy can interpret Markdown code, so the output is quite pleasing. There is one threat here though: unless you pay close attention to documentation when updating SQL code, it may be even more misleading than lack of it; it would probably also be quite painful to edit using Rails migrations. Sqitch (or the other tools I linked to would be a much better tool for this job.
Other documentation tools
There is a page with the list of documentation tools for SQL here. Unfortunately, the choice for PostgreSQL tools with HTML output is very poor. The most promising tool is SqlSpec by Elsasoft. It has features that SchemaSpy doesn’t, but it is pricey at the same time. I haven’t used it so I cannot easily recommend it, but it is worth mentioning in my opinion.
Going through tools on the list was a bit like a trip to the early 2000’s. Modern documentation tools based on Ruby made me spoiled, I can tell you that.
IDE
Having online documentation is convenient, because everybody has quick access to it, no matter what environment they use. But it is good to have an IDE which covers all of the needs and lets you write SQL code more efficiently. There are quite a few IDE tools and listing all of them is not my intent, but I will quickly write about some of the most obvious choices.
While an IDE is not as easily accessible as online documentation, it typically has the support of all of the database features. My tools of choice are DataGrip and PgAdmin 4. They are quite similar when it comes to layout: you have a list of databases with all of their tables, views, stored procedures, etc. and a window with details/queries on the right:
PgAdmin is free, which may be a selling point for some of you. DataGrip has a one-month free trial, which gives you a lot of time to see if you need to pay for its additional features. You might want to do that if you work on database engines other than PostgreSQL; DataGrip supports all of the most popular database engines, while PgAdmin is designed specifically for PostgreSQL.
As long as you make sure using such tools is encouraged in the team, there shouldn’t be much of a surprise when it comes to advanced database features. I think it is enough to add a mention in README, wiki etc. and stress it out when onboarding new developers. It may have an additional effect of making developers first think in SQL and only then in Ruby when writing SQL code.
Documenting stored procedures
I love projects with inline documentation. I love projects with inline documentation that is used to generate HTML even more. When I hear sentences like “you don’t need documentation, because I write self-documenting code”, I sigh with deep disappointment. The main reason why people say this is that they imagine documenting what code does. If you write clean object-oriented code, it may be true that what code does is obvious – but the reason for documenting your code should be the “why?” question.
There are times when you need to document both what the code does and what is its purpose. Especially when you have to use metaprogramming or some of the advanced optimisations techniques, the code may not be easy to read – and sometimes you can’t do anything about it.
I always try to think about other developers reading the code in the future, taking into consideration that they may have a different experience, background and domain knowledge. Will they be able to understand my intentions? If I am not sure, I document my code. For SQL code I recommend doing the same, especially that PL/pgSQL is not as easy to read as Ruby. You cannot foresee everything, and you shouldn’t be documenting language features, even though they may be new to you. But there are some things you can’t find in the documentation.
If you want a vivid example, try telling anyone that ci_lower_bounds function from my last article is self-documenting. With documentation it should look something like:
CREATE OR REPLACE FUNCTION ci_lower_bounds(upvotes_count INTEGER, downvotes_count INTEGER) RETURNS DOUBLE PRECISION
LANGUAGE plpgsql
AS $$
/*
Public: Calculates lower bound of Wilson score confidence interval for a
Bernoulli parameter. It is a mathematical formula that balances the
proportion of positive votes with the uncertainty of a small number of
votes. It answers the question: Given the votes I have, there is a 95%
chance that the “real” fraction of positive ratings is at least what?
More explanation can be found here:
http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
upvotes_count - number of positive votes
downvotes_count - number of negative votes
Returns double being lower bound of a confidence interval.
*/
BEGIN
RETURN (
(upvotes_count + 1.9208) / (upvotes_count + downvotes_count ) - 1.96 * Sqrt(
( upvotes_count * downvotes_count ) / ( upvotes_count + downvotes_count ) + 0.9604
) / (
upvotes_count + downvotes_count
)
) / (
1 + 3.8416 / ( upvotes_count + downvotes_count )
);
END;
$$;
Notice that I added documentation just before the body and not before the definition (as I would typically do in Ruby or any other language). The reason is that it would be ignored by the migrations system otherwise. I could use the COMMENT ON SQL command, but it is not that easily accessible. I am not sure if you can display it in DataGrip and in PgAdmin in the “Properties” tab, but it is much easier to read it looking at the code.
If a developer is not using an IDE they can see the documentation in the migrations code. It will be much easier when using Sqitch, but it is possible in the Rails migrations system as well (though it is not nearly as convenient in my opinion).
Conclusion
PostgreSQL has many exciting features, and you can use them in Ruby on Rails, despite the fact that it is not encouraged in the documentation. Be aware that it might be unexpected for some developers. I hope that the tools and techniques I described in this article will help you dive into SQL and use more of its features in your projects.